Abstract
The goal of Automatic Voice Over (AVO) is to generate speech in sync with a silent video given its text script. Recent AVO frameworks built upon text-to-speech synthesis (TTS) have shown impressive results. However, the current AVO learning objective of acoustic feature reconstruction brings in indirect supervision for inter-modal alignment learning, thus limiting the synchronization performance and synthetic speech quality. To this end, we proposed a novel AVO method leveraging the learning objective of self-supervised discrete speech unit prediction, which not only provides more direct supervision for the alignment learning, but also alleviates the mismatch between the text-video context and acoustic feature. Experimental results show that out proposed method achieves remarkable lip-speech synchronization and high speech quality by outperforming baselines in both objective and subjective evaluations. Codes and speech samples are publicly available.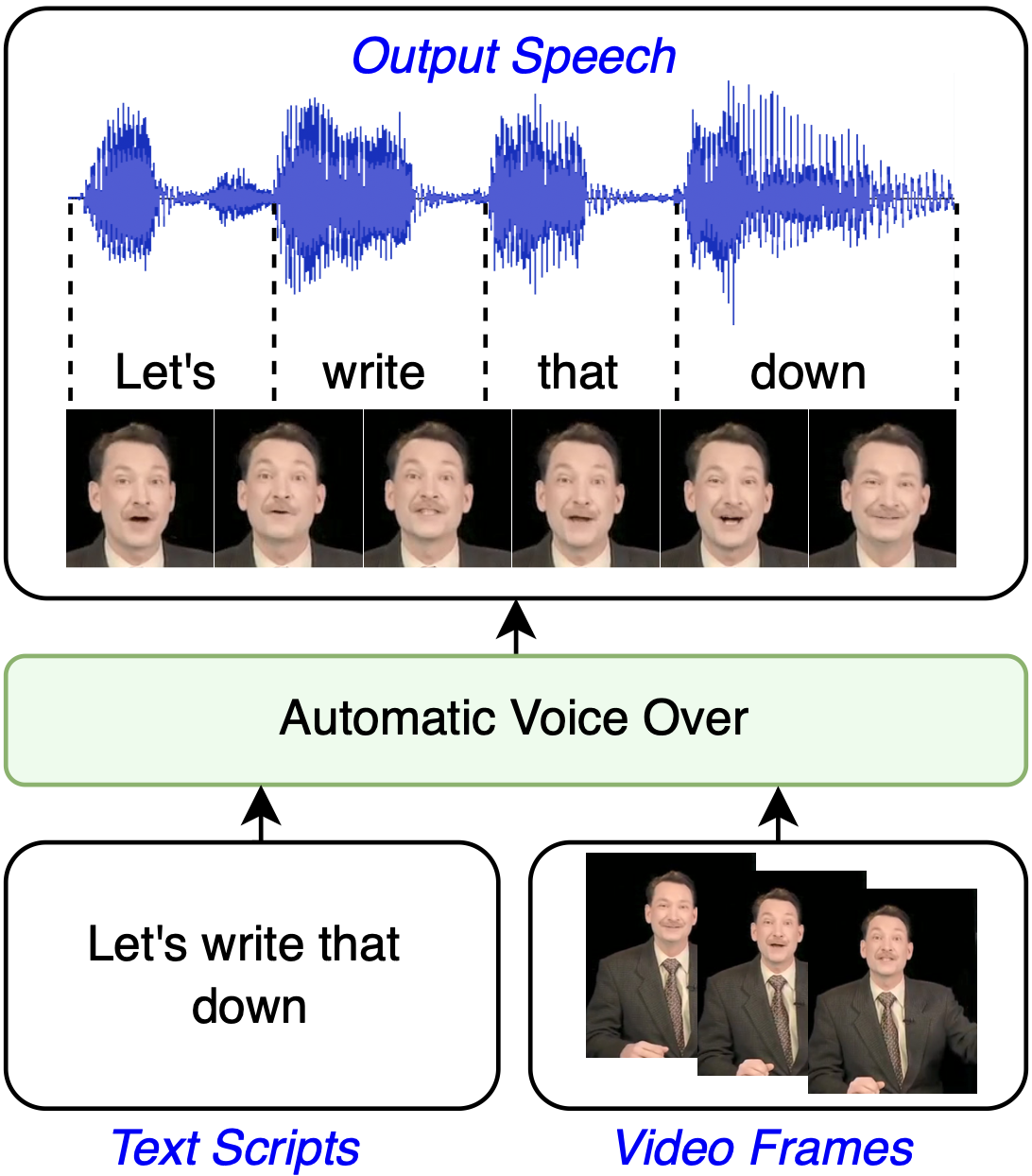
Fig. 1: An illustration of the AVO workflow:
The input to the system consists of video frames and corresponding text scripts, and the output is voice over speech audio in synchronization with the video.
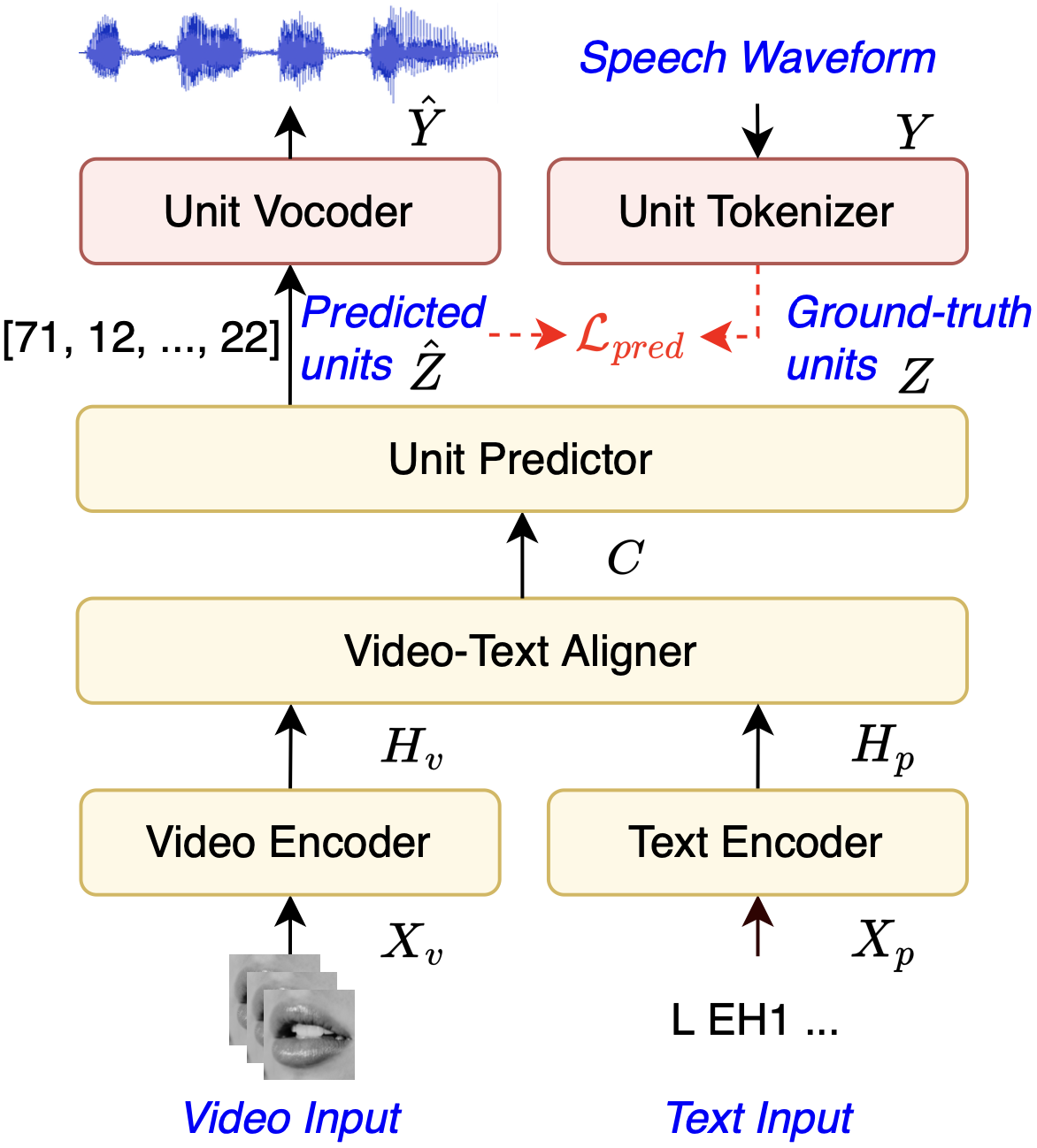
Fig. 2: The model architecture of the proposed DSU-AVO. Modules denoted with red color are pretrained and frozen during DSU-AVO training. Dotted arrows denote loss calculation. See Sec. 3.3 of our paper for a detailed description.
Frameworks
FastSpeech 2 [1]: a TTS baseline that generates speech conditioned only on text, without taking visual information into consideration.Neural Dubber [2]: an AVO baseline with the learning objective of mel-spectrogram reconstruction.
DSU-AVO: our proposed framework.
All frameworks use an identical text encoder. Neural Dubber and DSU-AVO use identical video encoder and video-text aligner for a fair comparison. Please refer to our paper for more implementation details. Code: https://github.com/ranacm/DSU-AVO
Speech Samples
| Ground Truth | FastSpeech 2 | Neural Dubber (reimplemented) | DSU-AVO (proposed) |
|---|---|---|---|
Sample 1: "One form of heterogeneous equilibrium is solids dissolving in liquids." |
|||
Sample 2: "Now, there's also nitrogen in the flask, but it doesn't matter." |
|||
Sample 3: "Now there's more properties to electromagnetic radiation and waves in general." |
|||
Sample 4: "Bright light, dim light, or no light?" |
|||
Sample 5: "The correct answer here is neutral and bright light." |
|||
Sample 6: "We're looking at the sublimation of iodine solid to form iodine gas." |
|||
References
[1] Y. Ren, C. Hu, X. Tan, T. Qin, S. Zhao, Z. Zhao, and T.-Y. Liu, “Fastspeech 2: Fast and high-quality end-to-end text to speech,” in International Conference on Learning Representations, 2021.[2] C. Hu, Q. Tian, T. Li, W. Yuping, Y. Wang, and H. Zhao, “Neural dubber: Dubbing for videos according to scripts,” Advances in Neural Information Processing Systems, vol. 34, 2021.